AI 기술이 급속도로 발전하면서 개인이나 소규모 팀도 강력한 언어 모델을 활용할 수 있는 시대가 왔습니다. 특히 한국어를 잘 이해하는 로컬 모델을 직접 조정하여 사용할 수 있다면, 클라우드 기반 거대 모델에 의존하지 않고도 다양한 AI 애플리케이션을 개발할 수 있습니다. 이 글에서는 홍정모 연구소에서 공개한 카카오의 카나(KANA) 모델 파인튜닝 방법을 배우며, 여러분만의 특화된 AI 어시스턴트를 만드는 방법을 알아보겠습니다.
한국어 로컬 모델 풀 파인튜닝 [홍정모 연구소]
본 영상은 홍정모 연구소에서 **한국어 로컬 모델 풀 파인튜닝** 방법을 소개합니다. LLM(Large Language Model)을 활용한 AI 에이전트 구축 시, 오픈 AI의 거대 모델을 클라우드에서 사용하는 방법과, 특
lilys.ai
LLM의 두 가지 길: 클라우드냐 로컬이냐, 그것이 문제로다
AI 에이전트를 개발할 때 가장 중요한 결정 중 하나는 어떤 언어 모델을 사용할 것인가입니다. 현재 우리에게는 크게 두 가지 선택지가 있습니다.
대형 클라우드 모델 vs 소형 로컬 모델
첫 번째 방법은 OpenAI의 GPT-4와 같은 거대 언어 모델을 클라우드에서 API로 호출하는 것입니다. 이 방식은 강력한 성능을 제공하지만, 사용 비용과 데이터 프라이버시 문제가 항상 따라다닙니다.
두 번째 방법은 특정 목적에 특화된 작은 모델을 로컬에서 직접 운영하는 것입니다. 이 방식은 초기 성능이 클라우드 모델에 비해 떨어질 수 있지만, 비용 효율성이 높고 데이터 통제가 용이합니다.
"최근에는 큰 모델이 항상 좋은 것이 아니라, 작은 모델 또한 괜찮다는 의견이 증가하고 있습니다. 현재로서는 대형 모델과 소형 모델이 각각의 장단점이 있으며, 양립 가능한 해결책이 될 수 있습니다."
흥미롭게도, 최근 연구 동향은 항상 큰 모델이 최선이 아니라는 점을 보여줍니다. 특히 특정 도메인에 특화된 작업에서는 잘 조정된 소형 모델이 더 효율적인 성능을 보일 수 있습니다.
한국어 LLM의 새로운 지평: 카카오 카나 모델
한국어 AI 연구의 가장 큰 도전은 언제나 고품질 한국어 모델의 부족이었습니다. 그러나 최근 상황이 빠르게 변화하고 있습니다.
한국형 LLM의 등장
LG의 엑사원(EXAONE)이 우수한 한국어 성능을 선보인 데 이어, 최근 카카오에서 공개한 카나(Ko-Alpaca) 모델은 오픈소스 한국어 AI 생태계에 활력을 불어넣고 있습니다. 이런 모델들의 공개는 한국어 AI 개발자 커뮤니티에 큰 기여를 하고 있습니다.
카나 모델의 특징
카나 모델은 크게 세 가지 유형으로 나뉩니다:
- 베이스 모델: 기본적인 사전 훈련만 완료된 상태로, 다음 단어 예측 방식으로 훈련되었습니다.
- 인스트럭트 모델: 사용자의 지시를 따르도록 추가 훈련된 모델로, 실제 사용 시 더 자연스러운 대화가 가능합니다.
- 임베딩 모델: 텍스트의 의미적 유사성을 판단할 수 있는 능력을 가진 모델입니다.
특히 카나 2.1B 모델은 크기가 상대적으로 작아 개인 컴퓨터에서도 쉽게 활용할 수 있다는 장점이 있습니다.
왜 파인튜닝이 필요할까요?
LLM 기술의 가장 큰 장벽은 항상 사전 훈련 비용이었습니다. 기본 모델을 처음부터 훈련하려면 엄청난 데이터와 컴퓨팅 자원이 필요합니다. 이런 이유로 파인튜닝이라는 효율적인 접근법이 주목받고 있습니다.
파인튜닝의 효율성
파인튜닝은 이미 사전 훈련된 모델을 특정 작업에 맞게 추가로 훈련하는 과정입니다. 이 방식의 주요 이점은:
- 적은 데이터만으로도 특정 도메인 지식을 모델에 주입할 수 있습니다.
- 짧은 훈련 시간으로 효과적인 결과를 얻을 수 있습니다.
- 비용 효율성이 매우 높습니다.
예를 들어, 의료 분야의 특수 용어나 회사 내부 문서에 자주 등장하는 전문 용어를 모델에게 학습시키고 싶다면, 전체 모델을 처음부터 훈련하는 대신 파인튜닝을 통해 효율적으로 목표를 달성할 수 있습니다.
카나 모델 파인튜닝 실전 가이드
실제 카나 모델을 파인튜닝하는 과정은 생각보다 간단합니다. 하지만 몇 가지 중요한 포인트를 알아두면 더 효과적인 결과를 얻을 수 있습니다.
데이터셋 준비: 성공의 첫걸음
파인튜닝에서 가장 중요한 부분은 데이터셋 준비입니다. 좋은 품질의 데이터셋이 없다면, 아무리 좋은 모델도 원하는 결과를 내기 어렵습니다.
기본적인 데이터셋 형식은 다음과 같습니다:
데이터셋을 구성할 때 주의할 점:
- 질문과 응답을 명확히 구분합니다.
- EOT(End of Text) 토큰과 같은 특수 토큰의 사용 방법을 이해해야 합니다.
- 원래 모델의 데이터 형식과 일관성을 유지합니다.
훈련 과정: 하이퍼파라미터의 마법
파인튜닝 시 조정할 수 있는 주요 하이퍼파라미터는 다음과 같습니다:
- 학습률(Learning Rate): 너무 높으면 모델이 발산하고, 너무 낮으면 훈련이 느립니다. 일반적으로 3e-5에서 5e-5 사이의 값을 사용합니다.
- 에폭(Epoch): 전체 데이터셋을 몇 번 반복할지 결정합니다. 소규모 데이터셋의 경우 10회 정도가 적당합니다.
- 배치 크기(Batch Size): 한 번에 처리할 샘플 수입니다. 메모리 제약에 따라 조정합니다.
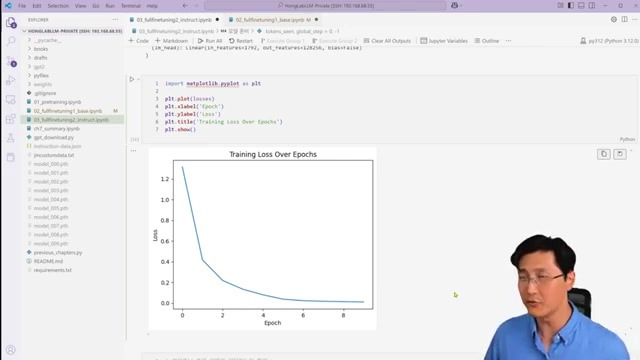
훈련 과정 중에는 손실 함수(Loss Function)의 감소 추이를 모니터링하는 것이 중요합니다. 손실 값이 지속적으로 감소하다가 안정화되면 훈련이 잘 진행되고 있다는 신호입니다.
베이스 모델 vs 인스트럭트 모델: 무엇을 선택해야 할까?
파인튜닝을 시작하기 전에 베이스 모델과 인스트럭트 모델 중 어떤 것을 사용할지 결정해야 합니다. 이 선택은 목표 애플리케이션에 따라 달라질 수 있습니다.
베이스 모델 파인튜닝
베이스 모델은 기본적인 언어 이해와 생성 능력을 갖추고 있지만, 지시를 따르는 능력은 제한적입니다. 이 모델을 파인튜닝하면:
- 특정 도메인 지식을 효과적으로 주입할 수 있습니다.
- 다음 토큰 예측 능력이 향상됩니다.
- 하지만 대화형 서비스에는 약간의 한계가 있을 수 있습니다.
인스트럭트 모델 파인튜닝
인스트럭트 모델은 이미 대화 형식과 지시 따르기에 최적화되어 있어, 챗봇이나 가상 비서와 같은 애플리케이션에 더 적합합니다:
- 질문-응답 형식의 데이터셋에 더 잘 적응합니다.
- 사용자 지시에 더 자연스럽게 반응합니다.
- 대화형 서비스에 즉시 활용 가능합니다.
"인스트럭트 모델은 질문에 대한 훈련을 하지 않아도 대답을 잘 수행하는 경향이 있습니다. 이런 모델은 특히 대화형 AI 서비스를 개발할 때 유리합니다."
실전 팁: 파인튜닝 성공의 열쇠
수많은 실험을 통해 얻은 실용적인 파인튜닝 팁을 공유합니다:
1. 데이터 품질이 양보다 중요합니다
대량의 저품질 데이터보다 소량의 고품질 데이터가 더 효과적입니다. 특히 전문 분야의 경우, 정확한 정보를 담은 데이터셋을 구성하는 것이 중요합니다.
2. 일반화 능력을 지속적으로 테스트하세요
훈련 중간에 데이터셋에 없는 질문으로 모델을 테스트해보세요. 모델이 단순 암기가 아닌 진정한 이해를 하고 있는지 확인하는 방법입니다.
3. 컨텍스트의 힘을 활용하세요
모델에게 충분한 컨텍스트를 제공하면 더 정확한 응답을 얻을 수 있습니다. 질문만 제공하기보다 배경 정보를 함께 제공하는 방식으로 데이터셋을 구성해보세요.
4. 오버피팅을 주의하세요
특히 소규모 데이터셋으로 훈련할 때는 오버피팅 위험이 높습니다. 검증 데이터셋을 활용하거나 훈련 에폭 수를 적절히 조절하세요.
한국어 LLM의 미래: 가능성과 도전
한국어 LLM 기술은 빠르게 발전하고 있으며, 향후 더 많은 오픈소스 모델이 등장할 것으로 예상됩니다. 이러한 흐름은 한국어 AI 생태계의 성장을 촉진할 것입니다.
상업적 활용의 가능성
현재 많은 한국어 모델들이 비상업적 용도로만 제한되어 있지만, 소규모 사업자를 위한 제약 완화 움직임이 있습니다. 매출 기준을 설정하여 특정 규모 이하의 상업적 활용을 허용하는 방식은 더 넓은 생태계 발전에 기여할 수 있습니다.
코드 스위칭을 통한 언어 학습
검색 결과에 나온 연구에 따르면, **코드 스위칭 커리큘럼 학습(CSCL)**은 다국어 모델의 효과적인 훈련 방법입니다. 이 방법은 인간의 제2언어 습득 과정에서 영감을 받아, 토큰 수준과 문장 수준의 코드 스위칭을 통해 모델이 점진적으로 새로운 언어를 학습하도록 합니다1.
이러한 접근법은 다양한 언어에 대응하는 모델을 개발할 때 유용하게 활용될 수 있으며, 특히 한국어와 같은 특정 언어에 특화된 모델을 개발할 때 참고할 수 있는 방법론입니다.
나만의 한국어 AI 비서 만들기: 지금 시작하세요!
로컬 LLM 파인튜닝은 생각보다 어렵지 않습니다. 특히 카나와 같은 소형 모델은 일반 PC에서도 충분히 훈련이 가능합니다.
다음 단계로 나아가려면:
- 허깅페이스(Hugging Face)에서 카나 모델을 다운로드하세요.
- 파이토치(PyTorch)와 트랜스포머(Transformers) 라이브러리를 설치하세요.
- 목적에 맞는 소규모 데이터셋을 준비하세요.
- 이 글에서 배운 파인튜닝 기법을 적용해보세요.
여러분만의 특별한 AI 어시스턴트가 탄생하는 순간을 경험해보세요!
마치며: 로컬 LLM의 무한한 가능성
AI 기술의 민주화는 빠르게 진행되고 있습니다. 거대 기업의 클라우드 API에만 의존하던 시대를 넘어, 이제는 누구나 자신만의 목적에 맞는 AI 모델을 직접 조정하고 활용할 수 있는 시대가 왔습니다.
여러분은 어떤 분야에 특화된 AI 어시스턴트를 만들고 싶으신가요? 의료, 법률, 교육, 혹은 여러분만의 특별한 관심 분야를 위한 AI 파트너를 상상해보세요. 로컬 LLM 파인튜닝을 통해 그 상상은 현실이 될 수 있습니다.
함께 고민해보세요: 한국어 LLM 기술이 발전함에 따라, 어떤 영역에서 가장 혁신적인 응용이 등장할 것 같나요? 여러분의 생각을 댓글로 공유해주세요!
🏷️ 태그
#한국어LLM #로컬AI #파인튜닝 #카나모델 #AI에이전트 #머신러닝 #카카오AI #모델훈련 #인공지능 #NLP #딥러닝 #홍정모연구소 #코드스위칭 #한국어AI #오픈소스AI
Mastering Local Korean LLMs: A Practical Fine-tuning Guide with KANA Model
As AI technology rapidly advances, we have entered an era where individuals and small teams can leverage powerful language models. Especially if you can directly fine-tune a local model that understands Korean well, you can develop various AI applications without relying on cloud-based large models. In this article, we'll learn how to fine-tune Kakao's KANA model, introduced by the Hong Jeong-mo Laboratory, and how to create your own specialized AI assistant.
Two Paths for LLMs: Cloud or Local? That is the Question
One of the most important decisions when developing an AI agent is which language model to use. Currently, we have two main options.
Large Cloud Models vs. Small Local Models
The first method is to call giant language models like OpenAI's GPT-4 via API in the cloud. This approach provides powerful performance but always comes with usage costs and data privacy concerns.
The second method is to directly operate smaller models specialized for specific purposes locally. This approach may initially have lower performance compared to cloud models, but it offers high cost efficiency and easy data control.
"Recently, there's a growing opinion that large models aren't always better, and smaller models can also be good. Currently, large and small models each have their own advantages and disadvantages, and can be complementary solutions."
Interestingly, recent research trends show that bigger models aren't always the best option. Particularly for tasks specialized in specific domains, well-tuned smaller models can show more efficient performance.
New Horizons in Korean LLMs: Kakao's KANA Model
The biggest challenge in Korean AI research has always been the lack of high-quality Korean models. However, the situation is changing rapidly.
The Emergence of Korean LLMs
Following LG's EXAONE, which demonstrated excellent Korean language performance, the recent KANA (Ko-Alpaca) model released by Kakao is bringing vitality to the open-source Korean AI ecosystem. The release of these models is making a significant contribution to the Korean AI developer community.
KANA Model Characteristics
The KANA model is divided into three main types:
- Base Model: Only basic pre-training has been completed, trained using next-word prediction methods.
- Instruct Model: A model further trained to follow user instructions, enabling more natural conversations in actual use.
- Embedding Model: A model capable of judging semantic similarity between texts.
The KANA 2.1B model, in particular, has the advantage of being relatively small, making it easy to utilize even on personal computers.
Why is Fine-tuning Necessary?
The biggest barrier to LLM technology has always been the cost of pre-training. Training a base model from scratch requires enormous data and computing resources. For this reason, the efficient approach of fine-tuning is gaining attention.
The Efficiency of Fine-tuning
Fine-tuning is the process of additionally training a pre-trained model for specific tasks. The main benefits of this approach are:
- You can inject domain-specific knowledge into the model with just a small amount of data.
- You can achieve effective results with short training times.
- It offers high cost efficiency.
For example, if you want to teach the model specialized terms frequently appearing in medical fields or company internal documents, you can efficiently achieve your goal through fine-tuning instead of training the entire model from scratch.
Practical Guide to KANA Model Fine-tuning
The actual process of fine-tuning the KANA model is simpler than you might think. However, knowing a few important points can help you achieve more effective results.
Dataset Preparation: The First Step to Success
The most important part of fine-tuning is dataset preparation. Without a good quality dataset, even the best model will struggle to produce desired results.
The basic dataset format is as follows:
Things to note when creating a dataset:
- Clearly distinguish between questions and answers.
- Understand how to use special tokens like EOT (End of Text) tokens.
- Maintain consistency with the original model's data format.
Training Process: The Magic of Hyperparameters
The main hyperparameters you can adjust during fine-tuning are:
- Learning Rate: If it's too high, the model diverges; if it's too low, training is slow. Generally, values between 3e-5 and 5e-5 are used.
- Epoch: Determines how many times to repeat the entire dataset. For small datasets, about 10 repetitions is appropriate.
- Batch Size: The number of samples to process at once. Adjust according to memory constraints.
During the training process, it's important to monitor the decline of the loss function. If the loss value continuously decreases and then stabilizes, it's a sign that training is progressing well.
Base Model vs. Instruct Model: Which Should You Choose?
Before starting fine-tuning, you need to decide whether to use a base model or an instruct model. This choice can vary depending on your target application.
Base Model Fine-tuning
Base models have basic language understanding and generation capabilities, but their ability to follow instructions is limited. When you fine-tune this model:
- You can effectively inject specific domain knowledge.
- The ability to predict the next token improves.
- However, there may be some limitations for conversational services.
Instruct Model Fine-tuning
Instruct models are already optimized for conversation formats and following instructions, making them more suitable for applications like chatbots or virtual assistants:
- They adapt better to question-answer format datasets.
- They respond more naturally to user instructions.
- They can be immediately utilized for conversational services.
"Instruct models tend to perform well in answering even without training on questions. These models are particularly advantageous when developing conversational AI services."
Practical Tips: Keys to Successful Fine-tuning
Here are practical fine-tuning tips gained through numerous experiments:
1. Data Quality is More Important Than Quantity
Small amounts of high-quality data are more effective than large amounts of low-quality data. Especially in specialized fields, it's important to create datasets containing accurate information.
2. Continuously Test Generalization Ability
Test your model with questions not in the dataset during training. This is a way to verify that your model is truly understanding rather than simply memorizing.
3. Leverage the Power of Context
Providing sufficient context to the model can yield more accurate responses. Try structuring your dataset to include background information along with questions, rather than just providing questions alone.
4. Be Cautious of Overfitting
The risk of overfitting is high, especially when training with small datasets. Use validation datasets or appropriately adjust the number of training epochs.
The Future of Korean LLMs: Possibilities and Challenges
Korean LLM technology is developing rapidly, and more open-source models are expected to emerge in the future. This trend will stimulate the growth of the Korean AI ecosystem.
Possibilities for Commercial Use
Currently, many Korean models are limited to non-commercial use, but there are movements to ease restrictions for small-scale businesses. The approach of setting revenue thresholds to allow commercial use below certain scales can contribute to broader ecosystem development.
Language Learning Through Code Switching
According to the research in the search results, Code-Switching Curriculum Learning (CSCL) is an effective training method for multilingual models. Inspired by the human second language acquisition process, this method allows models to progressively learn new languages through token-level and sentence-level code switching1.
This approach can be usefully applied when developing models that respond to various languages, and can be a methodology to reference especially when developing models specialized for specific languages like Korean.
Create Your Own Korean AI Assistant: Start Now!
Local LLM fine-tuning is not as difficult as you might think. Especially small models like KANA can be sufficiently trained on ordinary PCs.
To move to the next step:
- Download the KANA model from Hugging Face.
- Install PyTorch and Transformers libraries.
- Prepare a small-scale dataset suitable for your purpose.
- Apply the fine-tuning techniques you learned in this article.
Experience the moment your own special AI assistant is born!
Conclusion: The Infinite Possibilities of Local LLMs
The democratization of AI technology is progressing rapidly. Beyond the era of relying solely on cloud APIs from giant corporations, we've now entered an era where anyone can directly adjust and utilize AI models tailored to their own purposes.
What kind of specialized AI assistant would you like to create? Imagine an AI partner for medical, legal, educational, or your own special field of interest. Through local LLM fine-tuning, that imagination can become reality.
Think together: As Korean LLM technology advances, in which areas do you think the most innovative applications will emerge? Please share your thoughts in the comments!
🏷️ Tags
#KoreanLLM #LocalAI #Finetuning #KANAModel #AIAgent #MachineLearning #KakaoAI #ModelTraining #ArtificialIntelligence #NLP #DeepLearning #HongJeongmoLab #CodeSwitching #KoreanAI #OpenSourceAI
Citations:
'LLM' 카테고리의 다른 글
| 자동 회귀 모델의 한계를 넘어서: 얀 르쿤이 제시하는 인간 수준 AI의 청사진 (1) | 2025.03.22 |
|---|---|
| 🤖 LLM의 한계와 과학적 발견의 미래: 얀 르쿤의 통찰 (1) | 2025.03.20 |
| 똑똑해진 AI: RAG vs CAG, 인공지능의 지식 확장 전략 대결 (0) | 2025.03.18 |
| 생성형 AI의 숨겨진 적: 간접 프롬프트 주입 공격 완벽 분석 (0) | 2025.03.14 |
| 혁신적인 AI 에이전트 시스템의 세계: 단일 에이전트에서 멀티 에이전트 협업까지 (1) | 2025.03.12 |