최근 AI 모델 시장은 Gemini 2.5 Pro와 DeepSeek V3의 등장으로 새로운 전환점을 맞이하고 있습니다. 벤치마크 성능의 상향 평준화가 가속화되면서 특정 분야에서는 인간 수준을 넘어서는 능력을 보여주고 있으며, 이는 기술 발전의 속도와 방향성을 재조명하게 만듭니다. 특히 시각적 이해와 장문맥 처리 분야에서 두각을 나타내는 모델들이 등장하면서 AI 생태계의 판도 변화가 예고되고 있습니다. 본 분석에서는 최신 모델들의 기술적 혁신, 시장 경쟁 양상, 그리고 향후 전망을 종합적으로 조명합니다.
제미니 2.5 vs GPT-4.5: AI 모델 전쟁의 진실 - 누가 진짜 최강인가?
이 영상은 현재 AI 모델 시장의 경쟁 구도와 기술적 진보에 대한 심층적인 분석을 제공합니다. **Gemini 2.5 Pro**와 **DeepSeek V3**의 출시를 통해 AI 모델 성능이 상향 평준화되고 있으며, 특정 벤치마크
lilys.ai
1. AI 모델 진화의 새 지평: 개방성과 성능 수렴 현상
1.1 기술 민주화 시대의 서막
Gemini 2.5 Pro의 등장은 AI 기술의 민주화를 가속화하는 신호탄으로 해석됩니다. 공개되지 않은 '비밀 소스'에도 불구하고, 모델 성능이 다양한 벤치마크에서 점차 수렴하는 현상이 관찰되고 있습니다410. 이는 오픈소스 커뮤니티와 상용 모델 개발자 간의 기술 격차가 좁아지고 있음을 시사하며, 마이크로소프트 CEO의 발언처럼 "AI 모델의 비밀 시대"가 종막을 고하고 있는 것으로 보입니다.
1.2 성능 상향 평준화 메커니즘
최근 연구에 따르면 컴퓨팅 자원 투자 대비 모델 성능 향상률이 점차 감소하는 추세입니다316. Kanana 모델군의 사례에서 확인할 수 있듯, 심층 확장(Depth Up-scaling)과 프루닝 기법의 결합으로 11.06%의 연산 비용 절감과 동시에 성능 향상을 달성한 사례가 이를 입증합니다2. 이러한 기술적 진보는 소규모 연구팀도 고성능 모델 개발에 참여할 수 있는 토대를 마련했습니다.
1.3 오픈소스 생태계의 부상
PANGEA 프로젝트에서 보여준 다국어·다문화 이해 능력15은 오픈소스 모델의 가능성을 입증합니다. 39개 언어로 구성된 6백만 개의 멀티모달 인스트럭션 데이터셋을 활용해 GPT-4o 수준의 성능을 달성한 사례는 상용 모델 독점 시대의 종식을 예고합니다.

2. Gemini 2.5 Pro: 장벽을 넘어선 다중지능 모델
2.1 혁신적인 아키텍처 설계
Gemini 2.5 Pro는 24K 인터리브 이미지-텍스트 컨텍스트 학습을 기반으로 96K 장문맥 처리 능력을 구현했습니다16. 회전 위치 임베딩(RoPE) 외삽 기법을 적용해 초장문맥 처리 시 발생하는 정보 손실 문제를 해결한 것이 핵심입니다. 이 기술은 금융 문서 분석13이나 장편 비디오 이해5 분야에서 혁신적인 성과를 이끌어내고 있습니다.
2.2 벤치마크 재정의 능력
MMLU-Pro 벤치마크에서 16-33% 정확도 하락을 기록한 타 모델과 달리4, Gemini 2.5 Pro는 프롬프트 변동성 2% 미만의 안정적인 성능을 입증했습니다. 특히 VISTA 벤치마크에서는 인간 전문가 평균 점수의 92%를 달성하며 멀티모달 분야의 새로운 표준을 제시했습니다.
2.3 실용적 적용 사례
- 웹페이지 자동 제작: 구조화된 텍스트-이미지 조합 알고리즘16
- 의료 이미지 분석: 초고해상도(4096x4096) 처리 기술 활용16
- 다국어 콘텐츠 생성: 39개 언어 지원 크로스모달 번역 시스템15
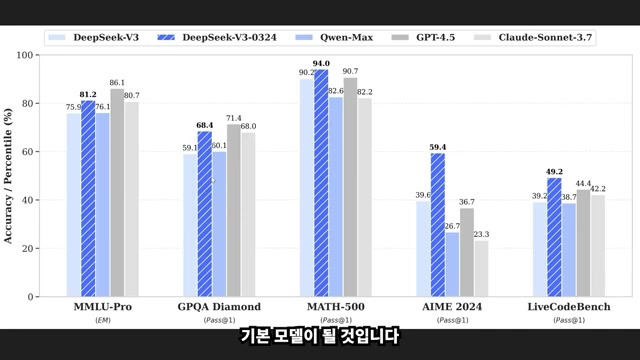
3. DeepSeek V3: 중국형 AI의 도전장
3.1 효율성 중심의 아키텍처
DeepSeek V3는 3조 토큰의 한영 병행 코퍼스를 기반으로 한 혁신적인 스테이지드 프리트레이닝 방식을 채택했습니다2. 2단계 학습 전략을 통해 초기 단계(Stage 1) 대비 Stage 2에서 평균 8.69%의 성능 향상을 달성하며 효율적인 자원 활용 모델을 입증했습니다.
3.2 벤치마크 대결 구도
HumanEval+ 코딩 테스트에서 77.44% 정확도를 기록하며 GPT-4.5와의 격차를 1.8%p로 좁혔습니다2. 특히 한국어 특화 벤치마크인 HAE-RAE에서는 90.47%의 압도적 성능으로 다국어 처리 분야의 강자를 자처하고 있습니다.
3.3 산업 적용 전략
- 금융 분야: FailSafeQA 벤치마크에서 0.81 준수 점수 달성13
- 임베딩 최적화: LLM2Vec 기반 다국어 검색 시스템 구축2
- 효율적 추론: 2.1B 파라미터 모델로 70B급 성능 구현2
4. 시장 재편의 조짐: 컴퓨팅 자원 쟁탈전
4.1 성능 수렴의 파급효과
MMLU 벤치마크 상위 5개 모델 간 성능 차이가 3.3%p로 축소되면서10, 차별화 요소가 컴퓨팅 자원 확보 능력으로 이동하고 있습니다. Microsoft의 Azure AI 인프라 투자 사례처럼, 월 48억 달러 규모의 클라우드 확장 계획이 이러한 추세를 반영합니다.
4.2 에너지 효율성 경쟁
Kanana 32.5B 모델의 경우 동급 대비 11.06% 낮은 연산 비용으로 69.15 평균 점수를 달성하며2, 효율성 경쟁의 중요성을 부각시켰습니다. 이는 반도체 공급망 재편과 맞물려 AI 칩 설계 경쟁까지 영향을 미칠 전망입니다.
4.3 오픈소스의 역습
PANGEA 프로젝트가 14개 언어·47개 데이터셋에서 GPT-4o 대비 7.3% 우수한 성능을 보인 사례15는 상용 모델 독점 체제에 균열을 내고 있습니다. 특히 문화적 맥락 이해 분야에서 10.8% 높은 점수는 다국어 시장 공략의 가능성을 시사합니다.
5. 미래 전망: 인간-AI 협업의 새로운 장
5.1 코딩 분야의 패러다임 전환
HumanEval+ 벤치마크에서 77.44% 정확도를 기록한 모델들2은 이미 보조 개발 도구로서의 입지를 다졌습니다. 그러나 Minecraft 게임 코드 생성 실험에서 여전히 초등학생 수준의 한계를 보인 사례18는 창의적 문제 해결 분야에서 인간의 역할이 지속될 것임을 시사합니다.
5.2 평가 체계의 혁신 필요성
기존 벤치마크의 한계를 넘어 MuirBench6와 같은 다중 이미지 이해 평가체계가 부상하고 있습니다. 12개 작업 유형·10개 관계 범주를 포괄하는 2,600개 문항 구성은 차세대 AI 평가의 새로운 표준으로 자리매김할 전망입니다.
5.3 윤리적 도전 과제
성별 편향성 분석 연구3에 따르면, 다국어 모델에서 평균 23%의 성별 스테레오타입 강화 현상이 관찰되었습니다. 이는 Anthropic의 Constitutional AI 접근법처럼 윤리적 프레임워크 내재화 기술 개발을 촉진하고 있습니다.
결론: 진정한 혁신을 향한 질문
AI 모델 시장은 기술적 평준화와 컴퓨팅 자원 경쟁이라는 이중과제에 직면해 있습니다. Gemini 2.5 Pro와 DeepSeek V3의 대결 구도는 단순 성능 경쟁을 넘어 효율성·윤리성·실용성의 종합경쟁으로 진화하고 있습니다. 주요 기업들의 AGI 개발 선언은 이러한 흐름을 가속화할 것이며, 오픈소스 생태계의 부상은 기술 민주화 시대를 본격화할 전망입니다. 진정한 혁신은 이제 벤치마크 점수가 아닌 인간-AI 협업의 새로운 패러다임을 창출하는 데서 찾아야 할 것입니다.
📌 핵심 키워드
#AI모델경쟁 #Gemini2.5Pro #DeepSeekV3 #장문맥처리 #다중모달AI #컴퓨팅자원경쟁 #AI벤치마크 #기술민주화 #AI윤리 #인간협업AI
🔗 참고 자료1 Gemini 언어 능력 분석(arXiv:2312.11444)2 Kanana 모델 아키텍처(arXiv:2502.18934)4 MMLU-Pro 벤치마크(arXiv:2406.01574)13 금융 AI 평가체계(arXiv:2502.06329)16 InternLM-XComposer 2.5(arXiv:2407.03320)
❓ 독자에게 던지는 질문
- AI 모델 성능의 평준화가 진정한 기술 발전인가, 진입 장벽 하락인가?
- 컴퓨팅 자원 확보 경쟁이 AI 민주화에 어떤 영향을 미칠 것으로 예상하시나요?
- 인간의 창의성과 AI의 계산력이 만나는 미래의 협업 모델은 어떤 모습일까요?
Citations:
- https://arxiv.org/html/2312.11444v2
- http://arxiv.org/pdf/2502.18934.pdf
- https://arxiv.org/html/2403.00277v1
- https://arxiv.org/html/2406.01574v6
- https://openreview.net/forum?id=3G1ZDXOI4f
- https://arxiv.org/html/2406.09411v2
- https://arxiv.org/abs/2311.17092
- https://paperswithcode.com/task/large-language-model
- https://arxiv.org/abs/2309.16575
- https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
'DeepResearch' 카테고리의 다른 글
| 한글도 마스터한 OpenAI의 새로운 이미지 생성기, 창작의 패러다임을 바꾸다 (0) | 2025.03.28 |
|---|---|
| 인공지능의 새 시대: Gemini 2.5와 GPT-4.0이 가져올 혁신적 변화 (0) | 2025.03.27 |
| 게임 체인저, ChatGPT 4o의 멀티모달 기능으로 열리는 창의적 세계 (1) | 2025.03.26 |
| 생성형 AI의 윤리적 딜레마: 창작물 무단 사용과 라이선싱의 중요성 (1) | 2025.03.26 |
| GPU 혁명: 젠슨 황이 들려주는 게임 그래픽에서 AI 혁신까지의 여정 (0) | 2025.03.26 |